









By Lotan Levkowitz Managing Partner, Grove

By Ron Netzerel Advisor


By Lotan Levkowitz Managing Partner, Grove
By Ron Netzerel Advisor
Based on an in-depth analysis of data from a dozen portfolio companies and more than 500 customers—impacting thousands of end users—This two-part article explores how successful AI companies build lasting competitive advantages through data and its implementation. In Part I, we discuss how data remains the foundation of sustainable AI advantages, and in which environments success patterns work best.
Drawing from our eight-year experience as early investors in AI-based systems at Grove Ventures, we’ve identified recurring patterns among companies in this space. This two-part article aims to share these “successful patterns for AI companies”, providing insights for entrepreneurs and investors in AI-driven innovation.
While acknowledging the uniqueness of each venture, we’ve observed that successful AI companies excel in two fundamental areas: first, in how they build and leverage their data advantages, and second, in how they thoughtfully integrate AI into human workflows. In Part I, we focus on why data remains king in the AI era and explore successful patterns for building lasting data-driven advantages. Part II will examine how successful AI companies are built through a trust-first approach that thoughtfully integrates AI with human expertise and existing workflows.
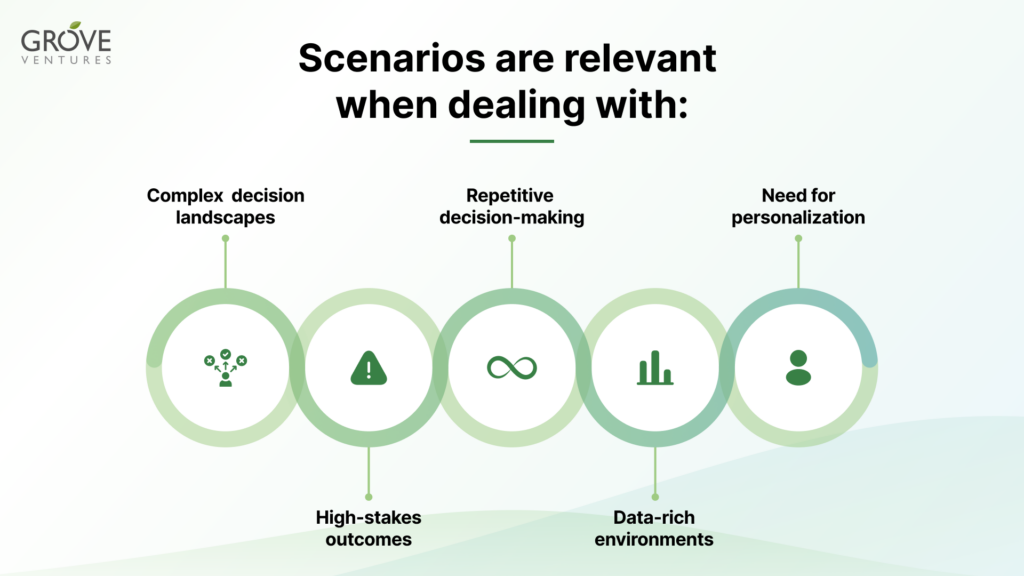
The successful patterns we’ve observed are particularly effective in domains where data-driven decision-making plays a crucial role in the workflow. The approach is especially powerful when applied to scenarios with the following attributes:
In these contexts, AI-powered systems that leverage comprehensive, structured databases can serve as invaluable decision support tools. By providing relevant, timely, and personalized insights, these systems can significantly enhance the efficiency and effectiveness of knowledge workers. This is particularly applicable to white collar positions, where professionals often deal with complex information processing, analysis, and decision-making tasks that can benefit greatly from AI assistance.
Most of the recent AI breakthroughs have been in the analytics & decision-making layer, where Large Language Models are projecting a step function in capabilities. While there has also been a new shift in the application layer with a free text-based interface, we still believe that the long-term value sits within the data layer.
In today’s rapidly evolving AI landscape, the data layer stands as the foundation upon which successful AI systems are built. While advancements in decision-making technologies and application interfaces are noteworthy, the true long-term value and differentiation lie in creating and maintaining proprietary data sets. When the core LLM evolves at an exponential pace, it is hard to maintain a long-term tech-related moat. In our era, we see better defensibility in the data layer itself and its integration to the workflow. This data layer and the different data sets it integrates, if curated and evolved thoughtfully, provide a unique competitive advantage that is difficult for others to replicate.
The ones who can create a proprietary data set – that keeps evolving and improving over time – and who can marry it to a significant value for the knowledge worker at the application layer, might be among the big winners of the Gen AI era.
No one is born with a ready-to-use, proven data set. Traditionally, we’ve seen companies build their own datasets through one of three different approaches described below. However, in today’s landscape, there’s also a fourth path that challenges this fundamental assumption:
And sometimes companies can combine a few methods; the bottom line is that there are different ways to build a data set – and that they vary by industry and product type. A worthwhile goal would be to end up with a defensible dataset, ideally based on free data, that improves with every addition of new data from customers.
Looking forward, we expect the emergence of LLMs to transform data strategy – companies can now be less rigid in their data collection approach since deriving insights from unstructured data has become dramatically simpler, thus encouraging companies to collect more data across all aspects of their operations.
Once we have the initial data set, there are a few methods we’ve seen to enhance its value dramatically.
Proprietary data sets create powerful competitive moats, and innovative companies find unique ways to build them. While the unit economics of collecting and growing these datasets become crucial at scale, early-stage companies should focus on establishing their data advantage first. Navina, for example, built its own models, specifically for primary care, before any such models existed based on medical literature and state of the art datasets – curated by Navina’s professional team of medical doctors.
ActiveFence is a good example here too – they began by manually identifying sources of hidden chatter, writing basic collection tools to kickstart their labeled proprietary dataset of content created by bad actors. Quickly after, they developed proprietary technology to scan the deep web and employed AI to source and identify the content on an unprecedented scale.
This exemplifies a broader pattern: successful companies often start with manual or seemingly unscalable data collection methods, but continuously innovate to develop unique, automated approaches to data gathering. The key is to envision the path to scalability while building your initial data moat.
While the initial effort to build your dataset is high, the magic happens if there’s a network effect – which improves the data as more customers use it.
In many cases, it is possible to build a system in a way that enables customer feedback to improve the quality of their data. In other cases, companies can get customers to integrate and share their first-party data to enrich the data set. In both of these instances, there is a network effect which improves the data (and the decision-making based on this data) with each customer so that the N+1 customer will get more value from day 1, and the competitive edge will keep on growing.
The key is ensuring that your data collection costs diminish over time while the value and diversity of your dataset grows. Take ActiveFence, for example: they began with models designed to detect multiple abuse areas. As their data collection processes became more efficient and their customer base and product usage grew, they were able to develop more specialized models for numerous subcategories of harmful content. This increasing granularity and specificity in their dataset weren’t feasible on day one but emerged naturally as their data collection processes matured and scaled.

Another example is OpMed.ai, which developed a novel algorithm for Operating Room and broader resource utilization. Their system’s procedure time estimations continuously improve as more real-world data is collected, enhancing optimization results for both existing and future customers.
Sometimes, the data itself is the core value proposition, not just fuel for algorithms. nReach exemplifies this through collaborative data enrichment: when their customers’ GTM teams use the product, they validate contacts by tagging them. This improves the quality of the contacts database with each new customer.
Nucleai’s collaboration with pharmaceutical companies and research partners has created a powerful flywheel effect. By integrating real-world data from clinical trials and translational research into its spatial proteomics platform, Nucleai continuously enhances the quality and diversity of its dataset. Each new partner contributes proprietary data and insights, which refine the algorithms and improve the decision-making for all users. This network effect ensures that every additional customer gains immediate value from an increasingly robust and comprehensive dataset, further solidifying Nucleai’s competitive edge.
While certain applications rely on data with perpetual validity (e.g., medical imaging), numerous scenarios derive significant value from data freshness. For instance, OnFire addressed a critical need among Go-To-Market (GTM) teams for real-time insights into their technical customers’ purchasing processes. Their approach enhances platform retention by providing continuous, evolving value to users. Furthermore, it informs product architecture decisions, necessitating designs that facilitate rapid and seamless flexibility and agility.
The time-sensitive nature of data not only ensures ongoing relevance but also drives user engagement through regularly updated, actionable insights. This model encourages frequent platform interaction, as users recognize the potential for new, valuable information with each visit. Consequently, the product design must prioritize efficient data processing and presentation mechanisms to deliver timely, pertinent information to users, thereby maximizing the utility and appeal of the platform.
In the era of AI, the data layer remains the cornerstone of long-term value and competitive advantage. Companies that can create, curate, and leverage proprietary datasets that evolve over time are poised to become industry leaders. These datasets, whether built through customer partnerships, smart public data curation, or proprietary methods, become increasingly valuable as they grow and improve with each user interaction. Ultimately, the companies that can effectively combine their unique data assets with significant value for knowledge workers at the application layer are likely to emerge as the major beneficiaries of the Gen AI revolution.
In the next article, “Successful Patterns for AI companies: Part II”, we will explore different aspects of integrating AI into human workflows.










